AWS Transcribe for long Zoom meetings
Posted on Thu 09 May 2019 in Articles
Introduction
I have been meaning to play around with AWS Transcribe, AWS' managed service for speech to text, for a while. This week I came across a good excuse. Our marketing department had a few longer meetings and they recorded those meetings in Zoom, the audio conferencing system we use. I asked for a copy of the recording, and with a 6 hour long mp4 in hand, tried to see what I could pull together.
Here are the steps I took. These are the correct sequence of commands for a Mac, but all tools (ffmpeg and awscli) on available on Linux and Windows as well.
Pre-processing audio files
First, I installed ffmpeg. This is easy via homebrew. I'm assuming the user already has awscli installed and configured with permissions to call out to both S3 and AWS Transcribe.
brew install ffmpeg
Next, I converted the mp4 to mp3.
ffmpeg -i recording.mp4 -f mp3 -ab 192000 -vn recording_audio.mp3
Next, I split the audio file into smaller chunks. The max recording length for AWS Transcribe is 4 hours (there are also restructions on file size). Note that in reality I tried to run a job first with the larger file and failed, then had to come back and do this step afterwards.
# Get length of recording
$ ffprobe -i recording_audio.mp3 -show_format 2>&1 | grep duration
duration=23797.944000 # 6.6 hours; max is 4 hours
# Split into hour chunks
$ ffmpeg -i recording_audio.mp3 -f segment -segment_time 3600 -c copy recording_audio.part-%03d.mp3
This is what files looked like after running all those commands.
$ ll
total 4055736
drwx------+ 1 un INIS\Domain Users 16K May 9 16:44 .
drwx------+ 1 un INIS\Domain Users 16K May 7 18:14 ..
-rwx------+ 1 un INIS\Domain Users 891M May 7 17:39 recording.mp4
-rwx------+ 1 un INIS\Domain Users 545M May 9 12:55 recording_audio.mp3
-rwx------+ 1 un INIS\Domain Users 82M May 9 16:43 recording_audio.part-000.mp3
-rwx------+ 1 un INIS\Domain Users 82M May 9 16:43 recording_audio.part-001.mp3
-rwx------+ 1 un INIS\Domain Users 82M May 9 16:43 recording_audio.part-002.mp3
-rwx------+ 1 un INIS\Domain Users 82M May 9 16:44 recording_audio.part-003.mp3
-rwx------+ 1 un INIS\Domain Users 82M May 9 16:44 recording_audio.part-004.mp3
-rwx------+ 1 un INIS\Domain Users 82M May 9 16:44 recording_audio.part-005.mp3
-rwx------+ 1 un INIS\Domain Users 50M May 9 16:44 recording_audio.part-006.mp3
Running transcription jobs
Next, I uploaded those split files to s3 using the awscli.
aws s3 cp . s3://mybucketname/transcribe/ --exclude "*.mp4,*audio.mp3" --recursive
Next, I kicked off a transcription job for each file using awscli. I use a couple custom settings to get the job to provide speaker labels. It was a big meeting, so I used the maximum number of speakers supported by transcribe (10).
for fn in `ls *.part-*`; do
echo $fn
aws transcribe start-transcription-job --transcription-job-name $fn --language-code en-US --media-format mp3 --media MediaFileUri=s3://mybucketname/transcribe/$fn --output-bucket-name mybucketname --settings ShowSpeakerLabels=true,MaxSpeakerLabels=10
done
I monitored those jobs in the AWS Transcribe console. That looked like this. You can see my original attempt to process the original recording mp4 file in 1 job, which failed because the recording was too long (>4 hours).
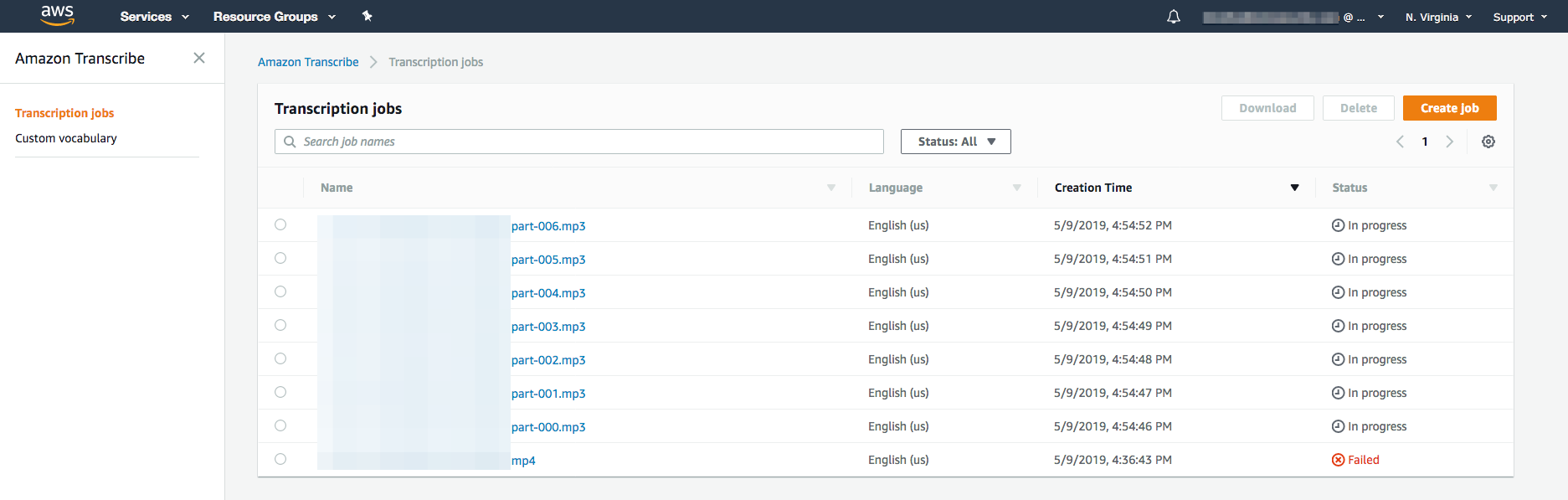
Once I saw that the jobs were completed, I noted where the result files were written to and downloaded them using the awscli.
for fn in `ls *.part-*`; do
echo $fn
aws s3 cp s3://mybucketname/$fn.json .
done
After looking through the output file, I saw that there was one section of the file that contained the entire transcription on 1 line. I concatenated these lines together. Since I broke my 6.6 hour recording into 7 chunks, I had a 7 line transcription of the entire meeting.
# Concat all
for fn in `ls *.mp3.json`; do
echo $fn
cat $fn | jq .results.transcripts[0] | jq .transcript -r >> transcription.txt
done
# Check size
# 7 lines (1 line per file)
# 50K + words
$ wc transcription.txt
7 57191 312196 transcription.txt
Reshaping output
This giant concatenated file is not the most friendly format to work with. I looked around for nice tools to create a better formatted output file from the set of files, but I didn't see a great tool that worked with multiple chunks of a single conversation, so I wrote a quick python program to handle this for me:
To understand the program, it is helpful to understand the schema of the transcription result JSON file. Unfortunately the documentation on this is not great (as of 2019/05/10). The JSON looks like this:
{
"accountId": "<AWS account ID>",
"jobName": "<transcribe job passed as the `transcription-job-name` parameter to `start-transcription-job` via `awscli` >",
"results": {
"items": [
<item>
],
"speaker_labels": {
"segments": [
<segment>
]
"speakers": <number of speakers, integer>,
}
"transcripts": "<>",
}
"status": "<job status, e.g. COMPLETED>"
}
The structure of items and segments looks like this:
# Item
{
"start_time": "<time>",
"end_time": "<time>",
"alternatives": [
{
"confidence": "<string encoded float between (0,1) >",
"content": "<content as string>"
}
],
"type": "pronunciation"
}
# OR
{
"alternatives": [
{
"confidence": null,
"content": "<punctuation mark, e.g. `.`>"
}
],
"type": "punctuation"
}
# Segment
{
"start_time": "<time>",
"speaker_label": "spk_<speaker number>",
"end_time": "<time>",
"items": [
<segment item>
]
}
# Segment item
{
"start_time": "<time>",
"speaker_label": "spk_<speaker number>",
"end_time": "<time>"
}
A few notes
- All the
_timefields are represented as string encoded floats, representing seconds since the start of the recording for the file being transcribed. - There are 2 types of items:
punctuationandpronunciation. Thepunctuationitems do not havestart_timeorend_timedefined.- This makes sense, but does make parsing a little more annoying.
- Speaker labels look like
spk_<speaker number>, where<speaker number>is an integer starting at0.
After using the python program to clean up the file, we get something like this:
[ speaker spk_5:recording_audio.part-000.mp3.json ] : ( 00:00:08:980 - 00:00:09:320 )
Alright let's get going.
[ speaker spk_6:recording_audio.part-000.mp3.json ] : ( 00:00:27:970 - 00:00:29:160 )
Should we start off with intros?
Each switch in the user speaking is marked by a header section that marks when that user is speaking and a time offset from the beginning of the conversation, across all N file chunks passed to the program.
Summary
With a couple lines of bash, ffmpeg, AWS tools, and a little python for formatting, we can put together some surprisingly decent transcriptions of long conversations.
I hope this is useful to someone else with similar problems to solve. Let me know if it helped you!